
- 深入浅出Docker:从配置到实战掌握容器化技术精髓
- 联通容器化大数据云平台探索与实践pptx
- 在消博会遇见未来:鸿蒙生态用“互联魔法”重塑智慧生活
- 偶数科技新专利:分布式数据库与大数据元共享系统将引领行业变革
- 容器云原生是数字化转型的基础设施
联系人:王经理
手机:13928851055
电话:13928851055
邮箱:sgbwre@163.com
地址:广州市天河南一街14-16号华信大夏四楼
联通容器化大数据云平台探索与实践pptx
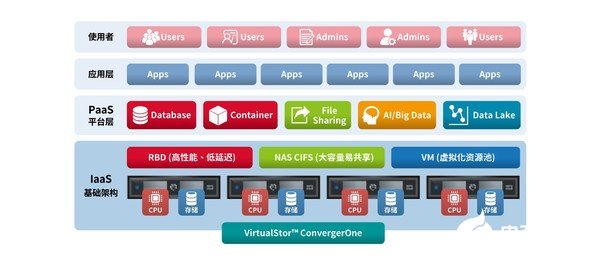
联通容器化大数据云平台探索与实践一、建设背景二、探索历程三、平台实践四、总结与展望1.1 大数据与云计算的发展历程大数据的目标是充分挖 掘海量数据中的信息, 以发现数据中的价值云计算的目标是通过资 源共享的方式更好地调 用、扩展和管理计算和 存储等方面的资源和能 力,以提高资源利用率, 降低企业的IT成本云计算可以为大数据平 台的计算和存储提供资 源层的灵活性大数据组件部署到云平 台上,作为通用PaaS能 力,为用户带来使用上 的便利和高效2009: CDH, Avro, Chukwa 2008: Hive, Pig, ZooKeeper 2007: HBase2006: Hadoop(HDFS+MapReduce), Solr2015: Kudu2014: Spark, Flink2012: YARN, Impala, Storm2011: MapR, Hcatalog, HDP, Kafka 2010-11: Crunch, Sqoop, Flume, Oozie1980-2002萌芽阶段2003-2006突破阶段2006-2009成熟阶段2009-2016应用阶段2013: 中国大数据元年2017-2022爆发阶段2010: OpenStack(IaaS)2009: vSphere(IaaS)2006: AWS(SaaS), Amazon EC2(IaaS),Zimki (PaaS)1999: Salesforce (SaaS)2016: OpenWhisk (FaaS), Fission(FaaS)2014: Kubernetes (CaaS), AWS Lambda(FaaS)2013: Docker (CaaS), Marathon(CaaS) 2012: Oracle Cloud(Iaas/PaaS/SaaS)2011: CloudFoundry (PaaS)1999SaaS出现2006IaaS/PaaS出现2013CaaS出现2014FaaS出现1.2 技术发展趋势:走向AI+Bigdata+Cloud 融合美国知名分析机构Wikibon把大数据技术发展大致分为3个阶段:Bigdata 1.0 :v 以海量数据存储、处理为主v 平台难以维护,数据开发困难Bigdata 2.0 :v Hadoop商业版出现v SQL on Hadoop 逐渐成熟v 以批处理、流处理为主Bigdata 3.0 :v 客户需求多元化v 技术栈复杂化v ABC走向融合MainstreamBig Data 3.0SimplicitySingle vendor platformAzure, AWS, Google,DatabricksFortune 500Big Data 2.0AdminHadoop ecosystemHortonworks, Cloudera, MapRTech companiesBig Data 1.0SpecializationTech vendors’ internal developmentMapReduce, BigTable, GFS, CassandraSpecializationSimplicityDevelopment1.3 中国联通构建了业界领先的大数据平台l 中国联通拥有集中的,企业级全域数据的存储中心、计算中心、能力中心和孵化中心数据服务能力开放对内应用对外变现(大数据公司)向上服务对内生产,同时支撑价值开放运营数据中心存储资料数据... ..Kaiyun平台官方.计算日志解析... ...能力流量查询... ...孵化技术引领资产化管理数据应用... ...顶层架构设计价值化运营统一数据模型全域贯穿能力化输出向下完成5大类、全域数据汇聚通信网络业务平台外部合作伙伴互联网IT系统1.3中国联通构建了业界领先的大数据平台国内领先的大数据平台2 海量的计算能力、存储能力2 PB级数据吞吐能力、统一数据服务能力2 企业核心数据资产管理能力2 助力数字化转型的服务型数据应用2 可价值变现的产品型数据应用数据治 理大数据对外应用大数据对内应用应 用SaaS数据服务能力封装/开放数据能力AI能力( )空间数 据能力(资源能力)业务 空间 数据库 智图人工 智能 引擎 智见能力开放平台(智汇)生产服务平台(智算)数 据 中 台开发测 试PaaSX86服务器(台)6097数据规模(PB)98.66551基于容器云的数据中心操作系统主机资源 存储资源1083基础 设施IaaS网络资源2017年 2018年 2019年2017年2018年2019年1.4 联通痛点l 全域数据汇聚和管理中心,沉淀了海量的计算能力、存储能力、数据能力。l 面临着如何实现资源智能调度、最大化利用、能力共享,进一步赋能各类合作伙伴应用创新、 促进数据价值变现的发展瓶颈。数据治 理大数据对内应用大数据对外应用应 用SaaS创新驱动2 构建能力共享生态2 急需支持租户自助使 用云化大数据相关资 源,赋能创新2 保障数据安全开放自身优化计算/存储资源使用不均衡资源弹性调度不足技术组件支撑不全手工运维效率低数据服务能力封装/开放业务 空间 数据库 智图人工 智能 引擎 智见能力开放平台(智汇)生产服务平台(智算)数 据 中 台资源能力数据能力AI能力 空间数开发测 试PaaS据能力)( )(基于容器云的数据中心操作系统基础 主机资源设施存储资源网络资源IaaS通过持续研究和探索,构建中国联通容器化大数据 云平台,解决痛点问题一、建设背景二、探索历程三、平台实践四、总结与展望2.1 历程回顾l 2016年至今,中国联通持续在大数据云平台建设方面投入力量l 完成了资源管理从无到有,资源调度及运维从“体力”到“脑力”的演变,逐步实现智能化管理和运营,为 企业数据生产与服务起到了降本提效的作用。飞跃阶段最初阶段优化提升物理部署人工划配系统运维半自动化部署半人工划配系统运维,简单监控一键部署按需自动分配、弹缩组件逐步丰富统一监控、智能运维HiveStormSpark……HadoopHbaseMPP……MysqlHiveSparkStormmysqlKafkatensorflowHadoopHbaseMPPRedis时序 数据库CaffeHiveStormSpark……HadoopHbaseMPP……MysqlRedisRedisYarnYarnMesosKubernetes+Dockerserver server serverserver server server serverserverserver server server server2.2 Kubernetes vs. Mesos通过研究、探索和实践,我们发现Kubernetes+Docker的技术路线更契合联通的实际需求。它几乎支持了所有的容器业务类型,包含长期伺服型(long-running)、批处理型(batch)、节点后台 支撑型(node-daemon)和有状态应用型(stateful application),也正是因为这个特点,k8s能够支持当前 大多数常见的大数据处理场景,如分布式数据存储(HDFS、Hbase)、离线分析(hive/Spark)、实时处理(Sparkstreaming)、数据挖掘(SparkMLlib),及深度学习框架(Tensorflow)等。KubernetesMesos技术出现时间2014年2014年调度级别二级调度(基于predicates和priorities两阶段算法)二级调度(FIFO,capacity scheduler,fair scheduler)生态活跃活跃且社区关注逐步上升活跃,社区关注逐步下降适用场景web应用,中间件及数据库,有状态服务,其他支持类型飞速 发展通用性高,混合场景成熟度高高应用案例分析Google、AWS、Redhat、Oracle、Intel、IBM、华为、阿里 百度等、 Twitter、Apple、Airbnb、Yelp等技术生态支持CNCF组织,由Google公司牵头组织主要由Mesosphere公司贡献技术实现开源产品种类繁多,实现难度低,成熟度较高原生框架实现难度高编排Docker需要Marathon实现调度功能2.3 与Rancher的合作中国联通在搭建Kubernetes + Docker的容器化平台过程中,引入了Rancher的产品部署和管理多个Kubernetes集群。中国联通的微服务开发运维管理平台 使用了Rancher Server,通过图形化和RKE两种方式对多个租户的kubernetes集群进行部署和管理:Rancher Server图形化RKE图形化部署和扩展集群图形化节点、资源和容器监控备份和容灾,提高集群可靠性部署/管理Rancher具有丰富的容器化实施案例 经验,是联通在支撑客户需求以及集 群故障恢复方面的坚强后盾。Kubernetes集群Kubernetes集群Kubernetes集群……Kubernetes集群Kubernetes作为开源产品,经常会有 重大安全漏洞,Rancher都是率先发 现并及时给出解决方案,为联通云平 台的安全保驾护航。一、建设背景二、探索历程三、平台实践四、总结与展望3.1 整体介绍2018年,基于Kubernetes+Docker,构建了中国联通容器化大数据云平台。基于统一服务集成框架Kubernetes Service Catalog,集中管理、部署多类PaaS能力,包括大数据基础服 务能力、中间件及数据库能力、数据集成工具能力、容器云能力、深度学习框架能力等,并支持灵活扩展。面向省分公司、子公司及内外部合作伙伴,实现大数据云化资源能力的自助开放,支持租户进行大数据平台 建设、大数据加工处理、模型训练及应用的开发部署。+租户+l 自助申请l 租户隔离l 应用持续集 成/部署创新孵化模型训练应用/微服务开发部署某省经营分析系统(数据加工)某省大数据生产平台租户数据集成工 具即服务云化ETL大数据即服务深度学习即 容器云服务 服务中间件/数据库即服务KafkaRedis+平台+l 集约管理l 智能调度l 动态弹缩统一服务集成框架(Kubernetes Service Catalog)Kubernetes+Docker资源管理资源调度资源隔离弹性伸缩安全管控负载均衡3.2 主要PaaS能力01 大数据基础服务组件(原子组件+场景化组合)HadoopSparkHiveHBaseHadoop基础服务,包括HDFS分布式 文件系统、统一资源管理框架YARN 等组件。基于内存的分布式计算引擎,大大提 高了海量数据加工处理的性能。开源SQL引擎组件,能够将普通SQL 语法转化成MapReduce作业,执行 批处理任务。Nosql数据库,支持结构化、半结构 化以及非结构化数据存储。Hbase表 动态可扩展,支持高并发的检索查询。StormZooKeeperIMPALA信息检索基于事件驱动模式的实时处理框架, 实时数据处理延时能够低至10ms级 别。Apache分布式应用程序协调服务组 件,主要用于大数据分布式组件的配 置、状态、元数据等信息的存储。高性能SQL查询引擎,将MPP与Hadoop架构进行融合;数据查询性 能远高于Hive。PB级别高速全文检索服务,提供高并 发支持,冷热数据隔离,以及字段精 确、模糊检索和快速统计功能。包括ElasticSearch等组件。数据仓库数据集市实时计算数据挖掘构建一站式数据仓库服务,提供数据 整合、加工、分析等全套数仓构建服 务,帮助打造数据核心。包括HDFS、 Hive、Spark等组件。适用于面向部门级的数据分析业务, 提供包括交互式分析引擎、OLAPCube引擎,支持自动化的报表应用构建。 包括 HDFS 、 Hive 、 Spark 、Rubik等组件。云上的流处理分析服务,对流数据进 行实时采集和处理,构建实时数据仓 库和实时应用,挖掘流式数据价值。 包括HDFS、SparkStreaming、Hbase等组件。数据挖掘开发平台,可进行机器学习 和AI应用的开发和训练,支持对各类 数据实现高度智能化的处理。包括Tensorflow、MxNet等组件。3.2 主要PaaS能力中间件及数据库服务组件Kafka Redis02MySqlNginx高性能HTTP服务器和反向代理 服务器。传统关系型数据库,支持single、一 主多从等多种部署模式。基于K-V的内存数据库,具有极高的 数据查询效率,常用于作为WEB系 统的数据缓存层。支持单机、哨兵、 集群等部署模式。高吞吐的分布式消息队列。数据集成工具03元数据管理云化ETL数据稽核管理支持对租户中的元数据进行管理, 包括元数据检索、数据血缘管理 分析等。采用图形化的数据流和工作流设计, 将分散的、异构数据源抽取,进行清 洗、转换、集成,最后加载到数据仓库 或数据集市中。全图形化规则配置界面,支持稽 核规则自动调度执行,针对稽核 出的数据质量问题,系统会自动 进行分类并形成数据处理工单。04 容器云应用/服务开发部署环境05 深度学习框架为模型训练提供 分布式计算框架及 开发工具支持对租户应用/服务开发、部 署、编排、动态弹缩、灰度升 级、并提供完整的可视化运维 监控3.3 技术架构租户A 租户B租户C租户D……租户N能力开放能力列表能力订购能力变更 能力退订Kubernetes Service CatalogOSB API OSB APIService Broker Service Broker中间件及数据库 微服务开发部署能力上架能力下架OSB APIOSB APIOSB APIOSB APIService BrokerService Broker Service BrokerService BrokerService BrokerService Broker大数据基础服务深度学习框架数据集成工具Mongo DBJupyterNotebooks开发/构建测试/发布CI/CD镜像仓库管理服务注册服务发现调用链跟踪限流/降级/熔断云存储RocketMQRedisMySQLES云化ETL三方服务扩展MxNetMPIPyTorchCaffe2TensorFlowImpalaKafka数据稽核管理HiveStorm元数据管理HadoopHBase容器管理(Kubernetes + Docker)资源管理资源调度资源隔离服务编排弹性伸缩安全管控负载均衡基础设施(主机 + 存储 + 网络)3.3 技术架构l 运用统一集成框架 Kubernetes Service Catalog,实现异构服务组件的统一纳管、自助拉起和在 线开放。使用业界标准的Open Service Broker API,支持第三方组件的接入和扩展。Service Broker A 容器化大数据平台KubernetesEtcd数据挖掘数据集市数据仓库 实时计算信息检索Open Service Broker APIService catalog API ServerKubernetes API ServerService Broker B 数据库与中间件OthersRedis KafkaService catalog ControllerService Broker C 深度学习框架OthersService Broker …… Service Broker ……3.4 支持场景l 租户自助构建大数据平台,进行数据生产l 提供大数据相关服务组件,供租户进行数据加工处理l 租户应用/微服务的开发和容器化部署l 提供建模环境及样本数据,供租户进行模型训练,赋能业务创新租户整体应用场景概览17%27%22%34%可视化选取数据获取分钟级容器化部署生产作业专属大数据平台省分大数据平台构建 大数据加工处理模型训练容器化应用/服务开发部署智汇资源自助开放 弹性伸缩 动态调度中国联通容器化大数据 云平台模型训练建模环境+批量样本数据大数据分析处理结果数据与自有应用场 景结合3.5 安全隔离容器化大数据云平台保障租户资源隔离、空间独立、数据加工过程私密、互不干扰,为租户提 供安全可靠的生产环境。服务隔离03 不同租户使用的服务属于不同的实例,彼此之间完全透明资源隔离01 租户有独立的网络、系统命名空间和存储0业务隔离4 通过Docker实现运行环境隔离,进程之间无法感知租户隔离和控制数据隔离每个租户可使用独立的HDFS用于 数据存储,租户间不做直接共享023.6 技术挑战多种PaaS能力集成Open Service BrokerKubernetes Service Catalog多Kubernetes集群互通定制Flannel网络插件,多集群共 用Flannel网络大数据服务容器化最小单位拆分亲和算法调度Headless service计算资源本地化亲和算法调度Yarn/Spark调度逻辑调整共享Domain socket3.6 技术挑战– 多样化PaaS服务集成l 遇到问题:容器化大数据云平台需要快速集成大数据类、数据库及中间件类、数据集成工具类等多种PaaS能力。没有统 一的集成接口。l 解决方案:基 于 业 界 先 进 的 Open Service Broker规范,通过 标准化接口快速对接各种PaaS组件平台,汇聚各种PaaS能力,形成技术生态, 为租户赋能。基于 Kubernetes ServiceCatalog,采用k8s扩展API和自定义资源原生技术实 现对服务从开通到退订的 全生命周期管理。Kubernetes Service CatalogClusterServiceClassServiceBindingClusterServiceBrokerServiceInstanceClusterServicePlanCredentialsOpen Service Broker APICatalogProvisionUpdateBindUnbindDeprovision实现实现实现实现Service BrokerService BrokerService BrokerService BrokerPaaS组件平台1 服务 服务 服务 服务PaaS组件平台2 服务 服务 服务 服务PaaS组件平台3 服务 服务 服务 服务PaaS组件平台n 服务 服务 服务 服务3.6 技术挑战– Kubernetes集群间网络互通l 遇到问题:需在多个Kubernetes集群部署各类PaaS能力。大数据组件在容器化部署之后,服务相关的所有POD 都是容器Kaiyun平台官方网络,自身暴露的通信端口在集群外都无 法访问,导致应用通过大数据组件原生的API调用 时遇到问题。l 解决方案:通过定制flanneld网络插件,两个K8S集群共用一套Flannel网络,实现跨集群pod IP直接连接,解 决K8s集群间的网络互通问题。Kubernetes集群1datanode podnamenode poddatanode podnamenode podETCDAPIServerAPIServerETCDHDFSKubeletKubeletKubeletKubeletflanneldflanneldflanneldflanneldapp1 app2Kubernetes集群2集群一集群二3.6 技术挑战– Hadoop容器化服务拆分l 遇到问题:采用多租户的方式对外提供大数据服务,每个租户都是隔离的。 这就要求需要在一个物理集群上能够部署多套Hadoop集群。挑战1. 挑战2. 挑战3.如何将Hadoop服务进行拆分? 如何自动完成角色规划?服务拆分之后,如何解决服务依赖以及服务发现问题?l 解决方案:1.将Hadoop按组件拆分成最小单位,确保能够独立部署;2.通过配置亲和/反亲和调度算法保证同一个集群的各个服 务能够合理部署,比如:同一集群的两个Namenode不 会调度在同一个物理机上;3.拆分完之后解决,服务之间的依赖和服务发现问题集群内使用Headless service服务之间通过DNS和配置注入进行服务发现集群外的访问通过--NodePort--Rest服务+LoadBalancer拆分Kubernetes存储网络监控3.6 技术挑战– Hadoop容器化计算本地化(1)物理机部署容器化部署ExecutorDatanodeExecutorDatanodeDomain Socketl 遇到问题:挑战1:Executor与Datanode数据不同pod,如何保证同一个集群的Executor和Datanode分布在相同的物 理主机上?挑战2:每个容器有一个独立IP,如何保证本地读写? 挑战3:每个容器独立的文件系统,如何保证DomainSocket优化?Domain Socket在安装集群前提前进行角色规划,确保YARN 的Nodemanger和Spark的Worker节点与Datanode都在相同的物理机上。通过判断IP是否一致决定是否进行本地读写Domain socket优化,免去本地io走tcp协议栈3.6 技术挑战– Hadoop容器化计算本地化(2)l 解决方案:第一步:采用K8S亲和性调度策略,确保统一集群的计算服务于Datanode调度到相同的物理机列表里。 第二步:更改Yarn/Spark调度逻辑,判断对应的计算切片是否在同一台host上。第三步:多个pod共享Domain socket,而且每个租户的hdfs的domain socket互相独立。GetBlockInfoNamenodeSchedulerExecutorExecutorNodemanagerNodemanagerBlock ReportAssign tasksDatanode DatanodeNode1DatanodeDatanodeNode2DatanodeDatanodeNodeManagerNodeManager集群1集群2Host1Host23.7 建设成效开放PaaS能力组件6大类,30余种开放标准化数据产品7大类,600余个省分租户44个2 部署4000余个容器服务实例,对100,000个事件跟踪分析子公司34个集群节点数437个,CPU6028核,内存37.52TB,存储13.09PB月均执行MR/Spark任务162,455个,执行数据调度任务15,261个102个租户入驻集团业务 部门24个l 2018,TMF Forum 开放数字生态大奖提名l 2018,大数据最佳产品奖,数据中心联盟大数据 发展委员会l 2018,中国联通集团科技进步奖3.8 后续探索方向-FaaS与云平台“Serveless”的初衷是帮助开发者摆脱运行后端应用程序所需的服务器设备的设置和管理工作,“FaaS” 将 “Serveless”这一框架提高到一个全新的层面,为云中运行的应用程序提供了一种全新的系统体系结构,不需 要在服务器上持续运行进程以等待 HTTP 请求或 API 调用,而是可以通过某种事件机制触发代码的执行。上层 快速软件平台(SaaS)认证服务函数函数函数平台(FaaS)客户端API网关函数函数数据库函数函数数据库应用平台 (PaaS/aPaaS)优势降低成本:开发者不需要为云中运行的整个服务器付费,只需要为执行 代码过程中消耗的资源付费缩放能力:可以通过事件触发的方式轻松地对不同服务进行缩放,而无 须考虑基础结构的运维和维护容器平台(CaaS)底层 灵活基础设施平台(IaaS)3.8 后续探索方向-物联网与云平台物联网通过信息传感设备,按约定的协议,将任何物体与网络相连接,物体通过信息传播媒介进行信息交换 和通信,以实现智能化识别、定位、跟踪、监管等功能。物联网是互联网基础上的延伸和扩展的网络,将各 种信息传感设备与互联网结合起来而形成的一个巨大网络,实现在任何时间、任何地点,人、机、物的互联 互通。SaaS物联网和云计算以及大数 据是密不可分的:数据分析数据管理设备管理云平台为大数据提供计 算资源和海量数据的存 储能力云平台为物联网应用提 供快速构建和集成的能力物联网设备产生的海量 数据需要大数据平台进行处理和分析FaaS函数平台PaaS持久化存储消息服务ETL工具数据库缓存IoTBig Data一、建设背景二、探索历程三、平台实践四、总结与展望4.1 总结与展望l 建设面向大数据处理的统一云化资源池,提供丰富的PaaS组件,为大数据平台构建和应用开发部署 提供快捷、高效的环境l 依托容器化大数据云平台,沉淀一系列技术能力及组件集合,推进企业核心数据上云,构建共性能 力及通用服务,打造企业级数据中台,赋能前端应用及BU团队快速创新,支撑业务发展前端应用与BU团队创新赋能前台、创新发展打造企业级数据中台多样化能力建设与开放互联网化协同运营能力汇聚、协同运营流处理框架批处理框架深度学习框架消息队列分布式文件系统分布式数据仓库NoSQL数据库关系型数据库异构资源纳管 资源隔离 资源调度 弹性伸缩 安全管控智能管理、提升效能容器化大数据云平台(Kubernetes+Docker)谢谢聆听!
2020年新人教版必修三《Unit4SpaceExploration》单元教案全套(附导学案).pdf
2023年12月中国热带农业科学院海口实验站第一批公开招聘工作人员4人(第1号)笔试历年典型考点解题.docx
原创力文档创建于2008年,本站为文档C2C交易模式,即用户上传的文档直接分享给其他用户(可下载、阅读),本站只是中间服务平台,本站所有文档下载所得的收益归上传人所有。原创力文档是网络服务平台方,若您的权利被侵害,请发链接和相关诉求至 电线) ,上传者
-
2025-04-14深入浅出Docker:从配置到实战掌握容器化技术精髓
-
2025-04-14联通容器化大数据云平台探索与实践pptx
-
2025-04-13容器云原生是数字化转型的基础设施
-
2025-04-13容器化趋势:探究云计算与微服务架构下的容器技术发展与影响
-
2025-04-13巨婴云譒ju3666
-
2025-04-13基于云计算的容器技术概述doc
-
2025-04-13云计算发展的新阶段企业需要怎样的容器技术?
-
2025-04-13容器云服务引擎是什么意思?






 客服
客服